小 Giao 之死 December 9, 2019 ## 机器人小 Giao 的前生今世 一个突然地想法,想到用个普通的摄像头做个预警机器人🤖,于是折腾了三四天,小 Giao 出生了。  *小 Giao 的头像经过模糊处理,头像来自 Allenzsy 在群里分享的第一个图片!* 小 Giao 威力巨大,为了防止小 Giao 统治人类世界,已经将其一棒子打死,尸体在: https://github.com/wangke0809/GiaoCameraRobot ------------ ## 目录 [TOC] ## 需求 需求分析: - 进入实验室检测:能够通过摄像头实时检测到有人进入实验室 -> Face Detection + Multi-label Classification - 检测结果通知:能够方便的接受监测结果 -> 使用钉钉群聊机器人 - 轻量级资源占用:工位上除了有个 2015 年办公的老电脑(i7-4790),还有个 GPU 工作站,因为借来的摄像头数据线长度不够,以及考虑到在工作站上跑实验时占用资源多会严重造成系统卡顿,所以决定在办公电脑上跑小 Giao ,所以需要保证运行小 Giao 的时候不能影响正常办公 -> 聚焦关键区域 + 上下帧图像变化量阈值 <!--more--> ## 整体实现 整体思路很简单,小 Giao 运行在办公电脑上,通过摄像头获取监控图像,分析,满足预警条件就发送通知。 小 Giao 短暂的一生经历了三个里程碑。 ### 阶段一:检测到人脸后发送通知  整体流程: ```flow st=>start: 启动小 Giao op0=>operation: 获取一帧图像 op1=>operation: 人脸检测 op2=>operation: 发送通知 cond=>condition: 检测人脸? sleep=>operation: 延时 0.5s e=>end: 结束 st->op0->op1->cond op2->sleep(right)->op0 cond(yes)->op2 cond(no,left)->op0 ``` 摄像头的分辨率为 640\*480,而实际上需要关心的区域只有下图中黑色框框选部分实验室入口区域,因此,仅需要在此区域检测人脸,检测到之后发送预警通知即可。 为了方便的选取区域,写了个 GUI 界面可用鼠标直接选取区域,选取后会输出选中区域位置和大小:  *图像经过模糊处理* 人脸检测算法使用 Tiny Face,由于在摄像头中人脸都比较小,所以选择了这个算法,放张算法对比图片来看下这个小人脸检测算法的厉害!  当使用 [0.25, 0.5, 1, 2] 尺度进行检测时,可以检测到更小的人脸,效果如下:  Tiny Face 在办公用的机器 CPU 上处理 640\*480 数据时,平均使用 1s 左右时间,处理黑色框中图像时,平均使用 0.2s 时间左右,极大减少了 CPU 占用率。 钉钉群机器人支持文本,MarkDown等格式通知,检测到人脸后直接发送通知。 小 Giao 在阶段一的 CPU 平均使用率在 35% 左右。分析可知,每个循环都会检测一次人脸,因此造成 CPU 占用率较高。 ### 阶段二:检测图像差异后检测人脸  *图像经过模糊处理* 整体流程: ```flow st=>start: 启动小 Giao op0=>operation: 获取一帧图像 op3=>operation: 检测图像差异 op1=>operation: 人脸检测 op2=>operation: 发送通知 cond=>condition: 检测人脸? cond2=>condition: 超过阈值? sleep=>operation: 延时 0.5s e=>end: 结束 st->op0->cond2 op1->cond op2->sleep(right)->op0 cond(yes)->op2 cond(no,right)->op0 cond2(yes)->op1 cond2(no,left)->op0 ``` 为了进一步提升效率,如果前后两帧图像差异不大,则可以认为检测区域处于静止状态,无需检测,既可以减少 CPU 占用,又可以当某人(哼!师姐)一直出现在检测区域且动作变化幅度不大时减少不必要的检测。 图像差异计算流程: ```flow op1=>operation: 灰度化 op2=>operation: 二值化 op3=>operation: 图像相减 op1->op2->op3 ``` 此时阈值的选取非常关键,决定 CPU 使用率和检测准确度,为了更方便的确定阈值,可视化了阈值变化曲线: 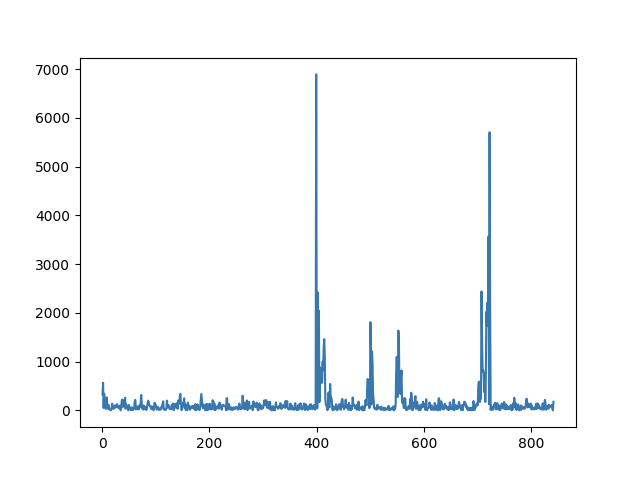 横坐标 400 和 750 处为有人经过,纵坐标为图像差值,为了增加检测窗口区间,将图像差值阈值设定为 500 。 钉钉发送 MarkDown 通知中可以添加图片,但是需要传到自建的存储中,经过测试,之前使用过的阿里云 OSS 上传速度较快,且 Python SDK 成熟好用(用过=。=),但是最后花了些时间看新浪 SAE 的 SCS 存储 API 文档,使用上传略慢的 SCS 做了存储,原因是:**SCS 可以薅羊毛!**每日有免费额度,经过计算几乎可以 0 成本一直使用。  阶段二,成长了的小 Giao 在没有人出现在检测区域时,CPU 占用率只有 1% 左右,有人出现在检测区域,CPU 峰值最高 25%。 跑了一天后发现了一些好玩的事情,比如,即便是用书故意遮挡面部,或者背对相机,也可以被 Tiny Face 检测到,因此也可以推测, Tiny Face 学到的模型,可能不仅仅针对人脸区域学习,还关联了身体部分的特征。  ↑ 遮挡面部  ↑ 背对相机 ### 阶段三:进出动作检测及人物识别 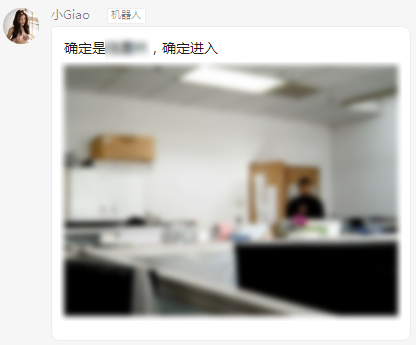 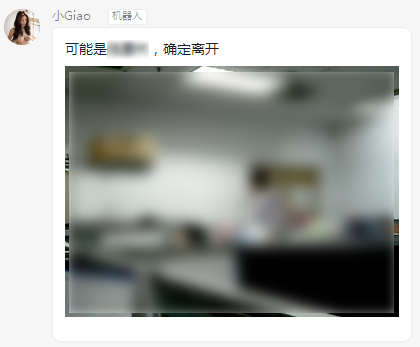 进出动作检测及人物识别就是说**可以检测出是谁?是进还是出?**简记为高级检测!方便「写」流程图。 整体流程: ```flow st=>start: 启动小 Giao op0=>operation: 获取一帧图像 op3=>operation: 检测图像差异 op1=>operation: 人脸检测 op2=>operation: 发送通知 cond=>condition: 检测人脸? cond2=>condition: 超过阈值? op3=>operation: 高级检测 sleep=>operation: 延时 0.5s e=>end: 结束 st->op0->cond2 op1->cond op2->sleep(right)->op0 cond(yes)->op3 cond(no,right)->op0 cond2(yes)->op1 cond2(no,left)->op0 op3->op2 ``` 那么问题来了,如何实现高级检测? 人脸识别?查阅了人脸识别文献后发现,人脸识别前置处理是人脸检测,对齐,在这个场景下人脸偏小以及很多情况下没有人脸,那么看来人脸识别就不适用了。 在这个场景单一,被识别人数固定的情况下,为了更多的利用场景信息,人脸以及体型,衣服颜色等信息,把这个任务当做 end-to-end 的分类任务可好?查阅了文献之后发现,相对于 Multi-class Classification 来讲,Multi-label Classification 更适合这个场景。 对于一个场景可以标注一个 3 + 9 维的标签,前 3 维分别表示 [进入,离开,不进不出],后 9 个维度对应九个人。写个 GUI 方便数据标注: 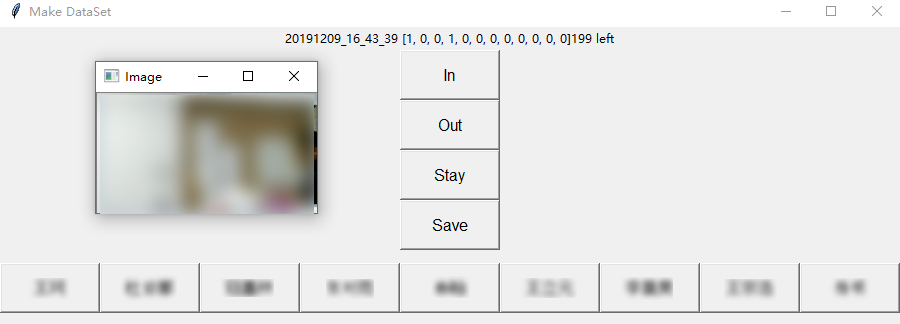 *图像经过模糊处理* 网络结构:使用预训练的 ResNet50 , layer4 加入 dropout , 最后一层 FC 改成 12 维输出的全连接层,在训练时仅更新 layer4 和 FC 层参数。 训练:Adam 优化器 + MultiLabelSoftMarginLoss 损失函数,使用客观指标 mAP 预估模型效果。由于初始时标注的数据较少,batch size 设定为 1 比较好,经过 50 epoch 训练,效果还不错。 在 CPU 上检选中部分区域用时 0.2s 左右,在 GPU 上训练时,顺便测了下速度,GPU 上只需要 0.01s 。 小 Giao 在生命的尽头,虽然增加了功能,但是 CPU 利用率几乎和阶段二一致。 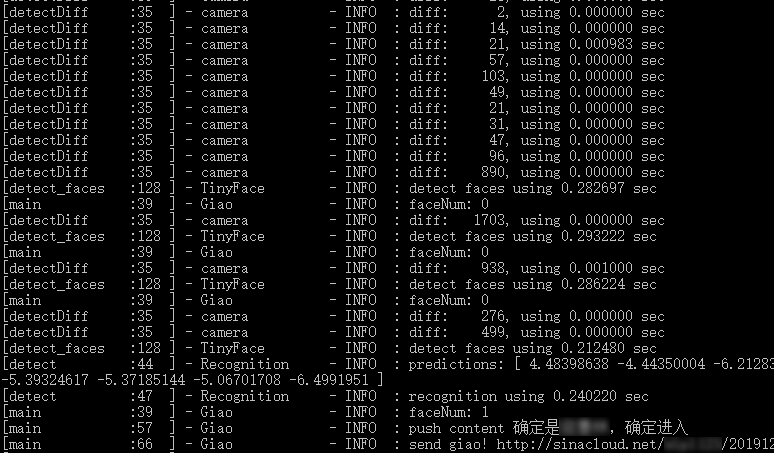 *配图:小 Giao 生前认真工作输出日志的样子* ## TODO 但是不准备做 - 图像异步检测:通过队列异步进行图像内容检测,保证图像内容不漏检,更容易控制 CPU 使用率,降低峰值 - 通知规则库:自定义通知规则,时间段,人物,动作都可以作为规则的输入变量,制定更灵活的通知 - 自动化在线学习:钉钉通知可以发送带按钮或者链接跳转,当发送预警时如果「高级检测」结果不对,可以直接进行标注,存储到云端,本地定时拉取云端标注的标签,当到达一定数量是开启本地 retrain,训练完经过测试集测试后更换模型 - 基于数据和状态的应用:比如统计某人的出入次数来客观判断某人的工作效率,查询室内人数,特定人员进入报警,再来个最早出勤 / 最晚下班周榜月榜,哈哈哈哈 ## 小 Giao 之死 虽然觉得小 Giao 很好玩,但是毕竟是一个监控的小 Giao,在小 Giao 壮大之前,还是狠心将其虐杀摇篮,一旦小 Giao 的事情败露,怕是要挨一顿胖揍了。 来小 Giao 的坟墓前:[->坟墓<-](https://github.com/wangke0809/GiaoCameraRobot "->坟墓<-") 烧个星星(star)吧,以缅怀这几天里小 Giao 曾经带来的欢乐,也可以替小 Giao 叉(fork)下土,来延续这份欢乐。 小 Giao 你好,小 Giao 再见!