如何开发一款区块链浏览器? May 20, 2020 ## 摘要 步入币圈大门后,除了钱包应用之外,用户最先接触的应该还有区块链浏览器。区块链浏览器不同于电脑和手机上浏览网页用的浏览器软件,而是指一个网站可以查询区块链上的具体信息。比如,给定区块高度,可以查询该高度区块的创建时间,包含了多少交易;给定一个地址,可以查询余额,该地址的所有交易记录等。当前以太坊上的数据量级已达亿级,如何进行数据持久化和查询呢?本文以以太坊为例,对区块链浏览器原理及存储细节进行分析总结。 <!--more--> ## 以太坊上有哪些交易类型 以太坊上 Native Token 交易,就是 ETH 交易,不过以太坊支持智能合约,开发者和机构可以在以太坊上创建合约并发行自己的通证,通过调用合约实现自己发行通证的转账,查询余额等。不同开发者可以分别为自己的合约编写不同的函数名来实现通证转移,那么问题来了,如果钱包类应用要兼容多家的通证,要分别知道他们是用了什么函数名,这么一来通用性较差。为了解决这个问题,以太坊社区制定了 ERC20 标准,该标准规范了通证合约的接口,比如,大家都要把合约转账的函数名编写为 transfer,如果转账成功要提交 transfer event,这么一来,钱包类应用只实现 ERC20 标准里规定的内容,就可以接入符合 ERC20 协议的通证了。 从 Token 的角度来看,以太坊上有 ETH Token,以及基于合约实现的 ERC20 和其他标准的 Token。交易为 ETH 转账交易,ERC20等 Token 转账交易。从合约的角度来看,交易有创建合约和调用合约两种交易类型,其中 ERC20 转账交易是通过调用合约的转账函数实现的。 ## 数据从哪里来 如果要解析区块数据,那么问题来了,我们从哪里获取区块数据呢? 常见的方法有三种: - RPC 接口:搭建全节点,通过调用全节点 RPC 接口获取区块和交易数据 - 优点:开发复杂度低,区块解析器和全节点可以在不同机器上运行 - 缺点:需要等待全节点更新区块完成后才可以获取数据,RPC 短链接密集 IO 操作时效率较低 - 实现:搭建全节点,使用 RPC 接口获取数据 - P2P 协议:ETH 全节点之间通过规定好的 P2P 协议进行数据交互,因此可以实现 P2P 协议,直接从对等节点获取区块和交易数据 - 优点:无需等待全节点同步数据,直接获取区块和交易信息 - 缺点:获取数据相对复杂,因为要实现 P2P 协议 - 实现:为了简化实现,可以在开源全节点的基础上增加数据解析入库逻辑 - 本地数据:ETH golang 实现的全节点中,本地数据通过 leveldb 存储,可以直接解析 leveldb 数据 - 优点:解析速度块,直接读取磁盘 - 缺点:需要了解 ETH 具体存储规则,以及需要维护最长链 - 实现:使用 leveldb 解析本地数据 ## 交易数据解析 分析完交易类型和数据源之后,我们在这里使用 RPC 解析数据的方式,作为 MVP 实现,我们只解析以下交易类型: - 解析 ETH 交易 - 解析 ERC20 Transfer 交易 - ERC20 合约直接调用 - ERC20 合约间接调用 - 解析创建合约交易 当全节点同步完成后,我们从第一个区块依次向后获取每个区块的信息,以及获取区块中的所有交易,对交易进行解析,解析完成的数据存入数据库中,用作查询使用。 ## 最长链选择 区块链本身是个多叉树结构,之所以称为链是因为大家只认可从根节点到子节点最长的路径,以最长链上的块为主块,在区块链产生区块的过程中,会产生很多叔块,因此在解析的过程中要一直沿着最长链的方向进行解析,那么如何保证最长链呢? 因为这里数据源依赖的是全节点 RPC 接口,全节点本身已经维护了最长链,因此,我们无需复杂的回溯逻辑,只需要对比已经解析高度为 h 的区块和全节点中高度为 h 的区块 hash 是否一致即可,如果一致证明本地解析的链为最长链,具体算法可描述为: - 区块分叉以全节点为准,同步时检测本地最新块高度 h 区块的 hash 和全节点高度为 h 的块 hash 是否一致,如果一致证明没有发生分叉,继续向后同步;如果不一致证明发生分叉,首先寻找分叉高度,然后进行回退。 - 寻找分叉点过程:从本地区块当前高度前一个高度 h 和全节点 h 区块的 hash 进行比对,如果一致,证明分叉点为 fork height = h + 1,如果不一致,继续向前 h = h - 1,直到找到分叉点。 - 回退过程:等待当前所有块解析完成后开始回退操作,删除 fork height 之后 block 的,及 block 中对应的交易。 - 回退完成后,从 fork height 开始同步。 ## 数据持久化 在说数据持久化之前,我们先来看看面对的是什么量级的数据,以及需要对数据的查询分析需求: - 数据量级:截止到目前,ETH 块高度近 1000 万,交易数量为 6.4 亿左右(ERC20 内部交易更多),各类 ERC20 合约 20 万左右,账户地址 1.3 亿左右 - 数据使用: - 首先是写入数据需求:解析到交易后进行写入操作,需要考虑写入效率 - 其次是查询需求:按照关键字段进行查询,如根据 from/to 地址进行交易查询;查询某个地址使用过的所有合约;查询某个合约的历史交易等 - 最后是统计需求:统计某个地址的最最大最小 ETH 交易或某个 ERC20 合约交易;查询某个 ERC20 在最近一个月内前转账金额最大的前 100 笔交易等;某个地址在某个块高度时的 ETH/ERC20 余额等 ## 数据库选型 常见的持久化数据库选择有以下类型: - 关系型数据库:家喻户晓的 MySQL,以及大兄弟 PostgreSQL 等 - 非关系型数据库:常见的 LevelDB,RocksDB 等 - 似关系非关系型数据库:MongoDB - 不是数据库:ElasticSearch 接下来来分析一下上述数据库的优劣。 ## MySQL 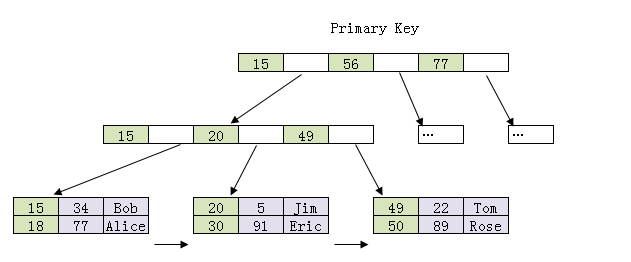 图 1 聚簇索引 B+Tree 示意图 以 MySQL 为代表的关系型数据库,对事务支持最好,其中 innoDB 引擎,采用的是 B+Tree 索引,有效减少了读取磁盘数据时 IO 次数,在数据表建立后,建立主键索引,数据实体存储在该索引的叶子节点上,如图 1 所示,主键查询数据时首先在主键索引树中查询数据所在叶节点,然后访问该位置读取数据;当查询非索引字段时进行全表扫描,当数据量大时,速度非常非常非常慢,当然,可以为查询字段建立索引,当查询多个字段时,可以建立联合索引,联合索引为非聚簇索引,查询到结果后需要回表,回表又需要在聚簇索引中进行一次查询,当数据量较小时,MySQL 的 B+Tree 索引树们看着是矮瘦的样子,查询速度较快;当数据量较大时,这些树全都变成了高胖大汉,查询效率自然降低。在早起的开源浏览器 Bitcoin ABE 中,便是使用的 MySQL,存储在单库单表中,不知道现在还能否使用。 对于关系型数据库的存储结构设计,大致可以使用区块表存储所有区块信息,交易表存储所有交易,以查询某个地址所有交易为例,需要在交易表中查询 from 和 to 为该地址的交易。 针对 MySQL 存储和查询当然也有解决方案,可以水平分库分表,比如区块表,交易表可以按照区块和交易 hash 取模进行分库分表;或者交易表可以按照不同的交易类型进行分库分表;查询时,分别从每个库或者每个表中查询数据,最后进行汇总。这么做说起来容易,可是分库分表对应用不透明,需要应用负责实现这些逻辑,实现起来有工作量。 ## NoSQL 非关系型数据库读写速度快,对事务支持没有 MySQL 那么优秀,在全节点中,BTC,ETH 等使用 LevelDB,CKB 等使用了 RocksDB。在节点解析中 Bitcore 使用了 MongoDB,BlockBook 使用了 RocksDB 。其中 MongoDB 支持分布式存储,LevelDB 与 RocksDB 则不支持分布式存储。 对于 LevelDB 与 RocksDB 这种 K-V 型数据库而言,存储结构可以使用区块 hash 作为键值存储区头信息以及所有交易 hash;使用交易 hash 作为键值存储具体交易内容,使用地址作为 key 存储该地址相关的所有交易 hash;以查询某个地址所有交易为例,首先根据地址查询所有交易 hash,然后使用每个交易 hash 查询具体交易信息。MongoDB 虽然使用 K-V 格式存储,但是针对索引字段支持额外的 B-Tree 索引。 使用 K-V 进行查询时,查询速度快,不像 MySQL 那样需要从 B+Tree 查询,可以使用 key 直接定位数据位置;但是短板也很明显,查询时需要将该 key 下所有数据加载到内存,如需分页等操作,实质上也是查询出所有数据,在内存中进行分页。当然也有可以想到的解决方案,针对地址 address 存储交易时,由于解析是按照时间顺序解析,存储格式可设定为 key = address + page1 进行存储固定 size 交易 hash,当超过该 size 是启用 key = address + page2 进行存储,这样查询时便可以进行分页查询,应用需要实现这个分片逻辑。 ## ElasticSearch 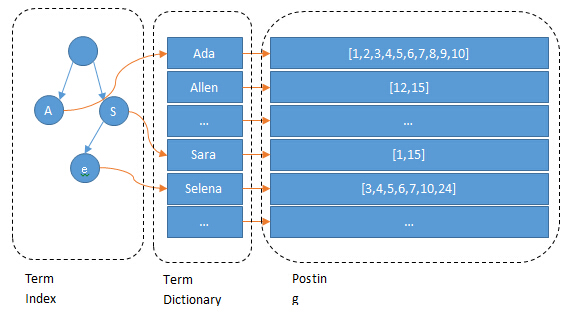 图 2 倒排索引示意图 ElasticSearch 不支持事务,使用倒排索引,如图 2 所示,通过字典书管理 Term,每个 Term 下存储包含该 Term 的所有文档的 docId 。MySQL 为了减少磁盘 IO 和 Random Access 使用 B+Tree 组织数据,ElasticSearch 通过 Term Dictionary 分块减少 Random Access。为了防止多条件查询时查询出每个条件对应的 docId,然后利用 Skip List 进行 docId 集合合并,范围型查询使用 BKDTree 进行索引。天生支持横向扩容,数据可分布在从节点分片内,查询时主节点从多个从节点查询然后在内存中合并,这个过程由集群处理,对于应用程序来说是无感知的。而且支持设定 Index Lifecycle Policies,自动拆分 Index。 这么来看,ElasticSearch 在区块链数据存储和查询的场景,整体来看内部支持横向分片,查询性能好,且内置了各种聚合功能,似乎综是个比较好的选择。在 EOS 历史数据解析中,Hyperion-History-API 项目选择了 Elasticsearch 作为存储。 ## 整体设计方案 ### 解析器设计 在解析数据的过程中,包含区块数据读取解析和数据持久化写入的过程,整个解析器的瓶颈在于数据读取解析速度和数据写入速度。为了均衡二者,常见的方案是在数据读取解析和数据写入之间搭建缓冲管道,整体思路如下: - 数据读取解析:固定线程数进行数据读取解析,解析后结果存入 queue 中 - 数据传输队列:queue 设定最大消息数阈值,防止 queue 无限增大占用过多资源 - 数据写入:从 queue 中获取消息,使用固定线程数进行写入 **如何保证数据的完整性呢?当数据读取和数据写入出错时如何处理?** - 数据读取失败队列:数据读取失败后加入到失败队列,数据读取时首先检查失败队列,并优先读取失败队列中任务 - 数据写入失败:类似数据读取,可以单独使用个 queue,或者可以把失败的数据再送回数据读取解析后保存的数据传输队列中,也方便控制写入速率。 - 解析器启动时首先检查完数据完整性,去除重复区块,解析缺少区块 **解析器如何优雅的退出(确保区块数据完整):** - 停止数据读取任务添加,等待当前线程池内数据解析完毕 - 消费数据传输队列中所有消息 - 停止程序 - 停止后保证区块连续和不缺少区块 **因为异常退出,或需要检查数据完整性:** - 从最大高度开始寻找缺少或者重复的区块数据 - 补足缺少数据和处理重复数据后从当前最大高度开始正常解析 **亿级数据如何快速查找缺少的高度和重复的高度?** 基于分而治之思想快速完整性检查:假设从高度 h 到 h - N 查询区块数量,如果数量等于 N,认定不缺少或不重复(解析过程中发现出现了 Elasticsearch 提交成功,也为报错,但是没有存储上的区块,未遇到重复区块)。在该假设的基础上,当全部区块数和最高区块数不匹配时,N 取 10万,从最大高度向下检查,当不满足查询的区块数等于 N 时,从 h 到 h - N / 2 和 h - N / 2 + 1 到 h - N进行二分区块数判断,当二分区间为 N / 8 时查询所有数据进行遍历。 全量完整性检查:每次取 1 万高度,进行缺少重复判断。 ## ElasticSearch 数据存储 如何优雅的使用 ElasticSearch 进行数据存储?常见的使用 ElasticSearch 进行数据分析的方式是数据存储到关系型数据库中,然后从关系型数据库中同步到 ES 中。考虑到区块解析无需事务支持,仅包含写入操作(完整性检查和处理分叉时包含删除),可以直接将数据存储到 ES 中,参考 Hyperion-History-API 项目,可以进行以下设计: - 解析器启动时向 ES 中写入 Index Lifecycle Policies - Index Lifecycle Policies 中设定满足指定数据大小和时间后进行 rollover,避免分片过大造成查询效率降低 - 针对所有 index 设定 Index Template,制定设置好的 Index Lifecycle Policies, 需要查询的字段设定为 keyword,无需查询的字段 disable index - 针对金额字段,为了数值准确,使用 keyword 保存精确值,使用 double 保存不精确值,保存数据类型方便后续 range 查询和聚合等 - 数据通过 bulk API 批量写入,减少网络 IO 次数 数据查询上,可以利用 ES 丰富的查询规则实现查询,以满足功能需求,具体细节不再赘述。 ## 同步过程 - 解析器通过 RPC 获取数据时必须等全节点同步完成,否则在同步过程中可能面临全节点区块不连续,分叉等问题,同时大量查询请求也影响全节点同步区块数据的性能 - 解析前 300 万区块耗时 6 小时左右,在 MVP 的设计中,数据传输队列以区块和区块内所有单位存储,解析器一个线程负责解析一个区块,此时解析器线程和数据传输队列可以设定大一些,此时由于前 300 万区块内交易较少,解析速度高于持久化写入速度,可以观察到数据传输队列接近队列最大值 - 后续区块共耗时 50 个多小时,由于每个区块内交易明显增加,此时数据传输队列中缓存的区块数据经过观察一直为个位数,此时读取速度成为瓶颈,为了降低节点压力和减少 IO 耗时,此时解析器线程数设定小一点 - 同步到最新区块后真的出现过不止一次分叉,经过上文中提到的分叉检查算法检查可解决分叉问题 - 磁盘 IO 速度和 CPU 速度很重要 共同步了 967 万区块头信息,6 亿 8 千万交易信息。 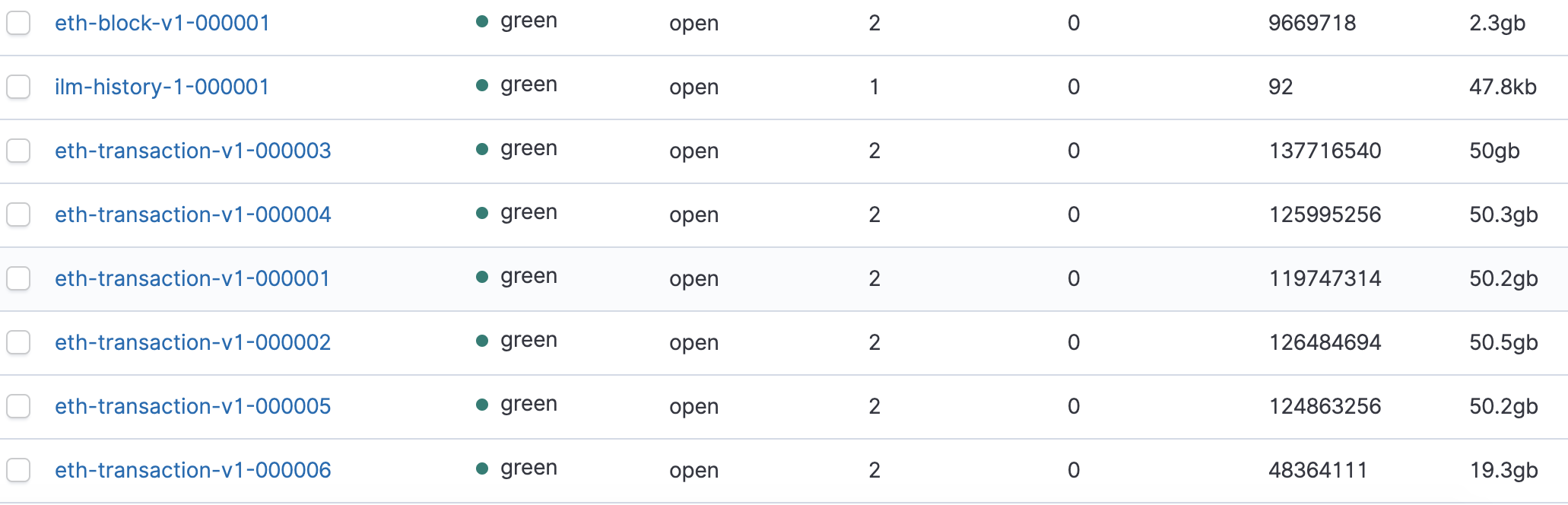 图 3 解析的所有数据 ## 数据分析 为了方便查询和展示,使用 Kibana 进行数据查询和可视化,后续根据需求通过 ES 丰富的查询功能制定相应接口即可。 ### 浏览区块数据 可以根据高度和 hash 进行查询区块数据和对应的交易数据。区块文档数和高度一致,证明没有缺失区块和重复区块。 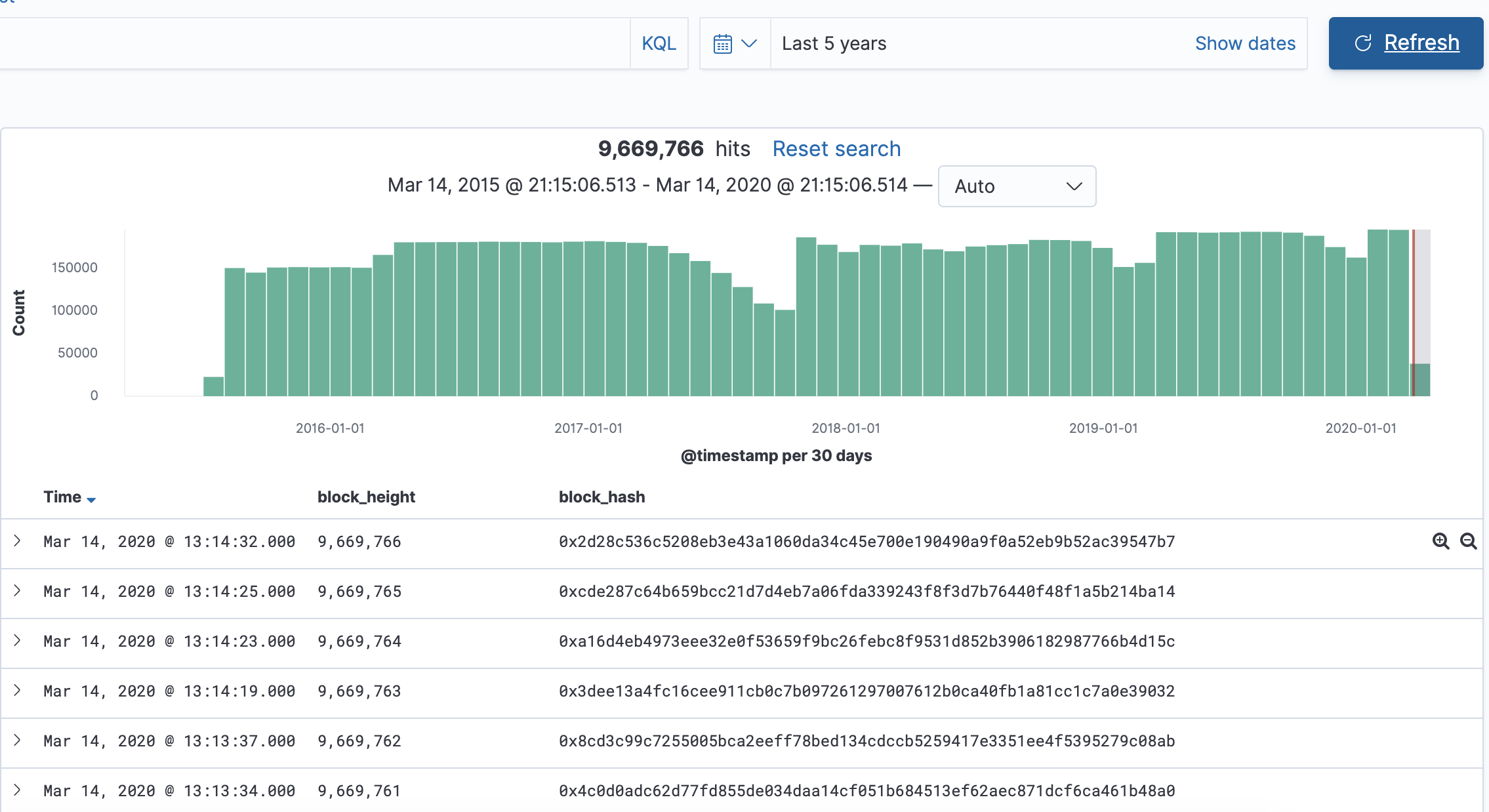 图 4 区块数据浏览 可以查询某个地址/合约指定日期内交易等。 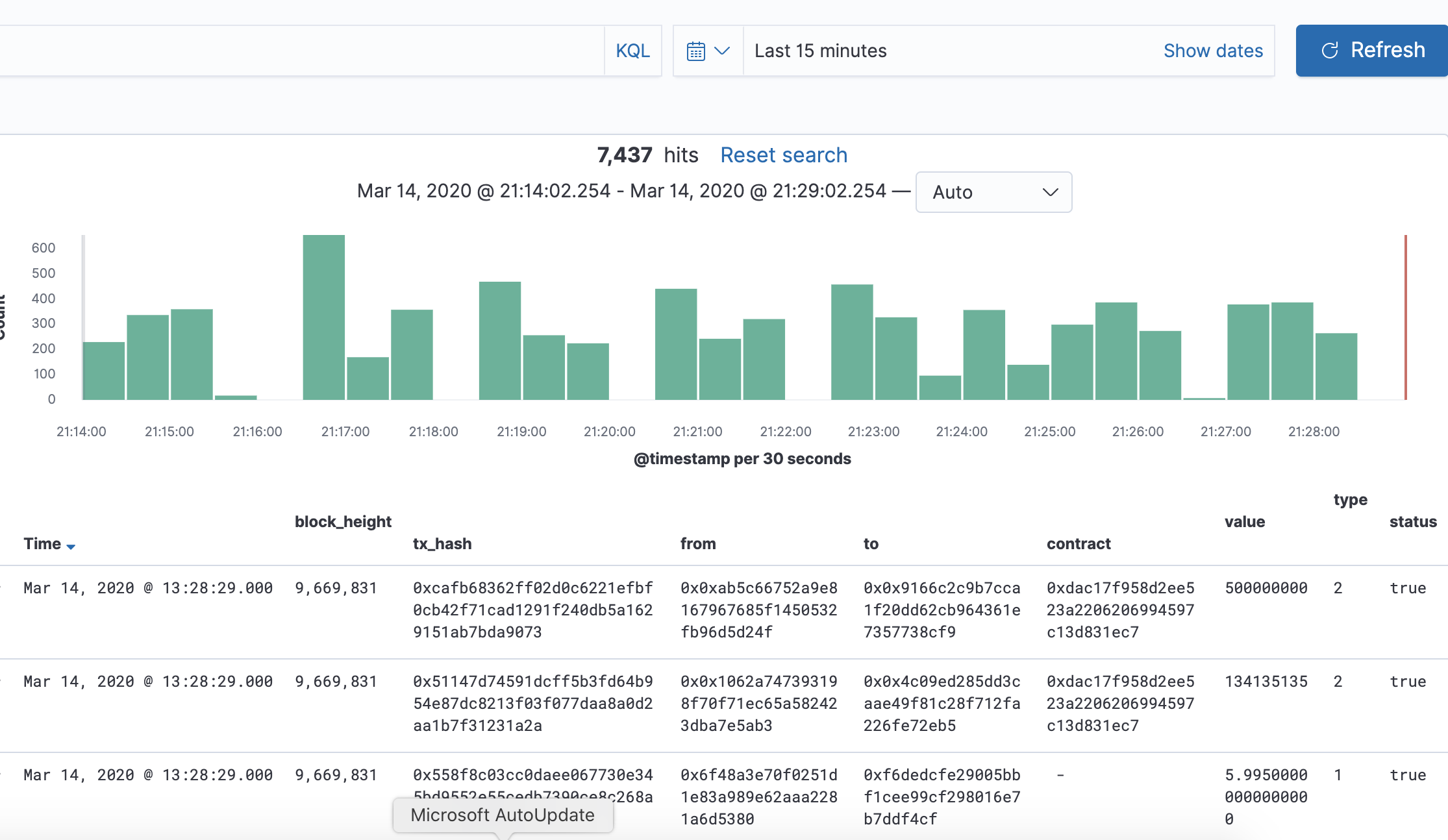 图 5 查询交易信息 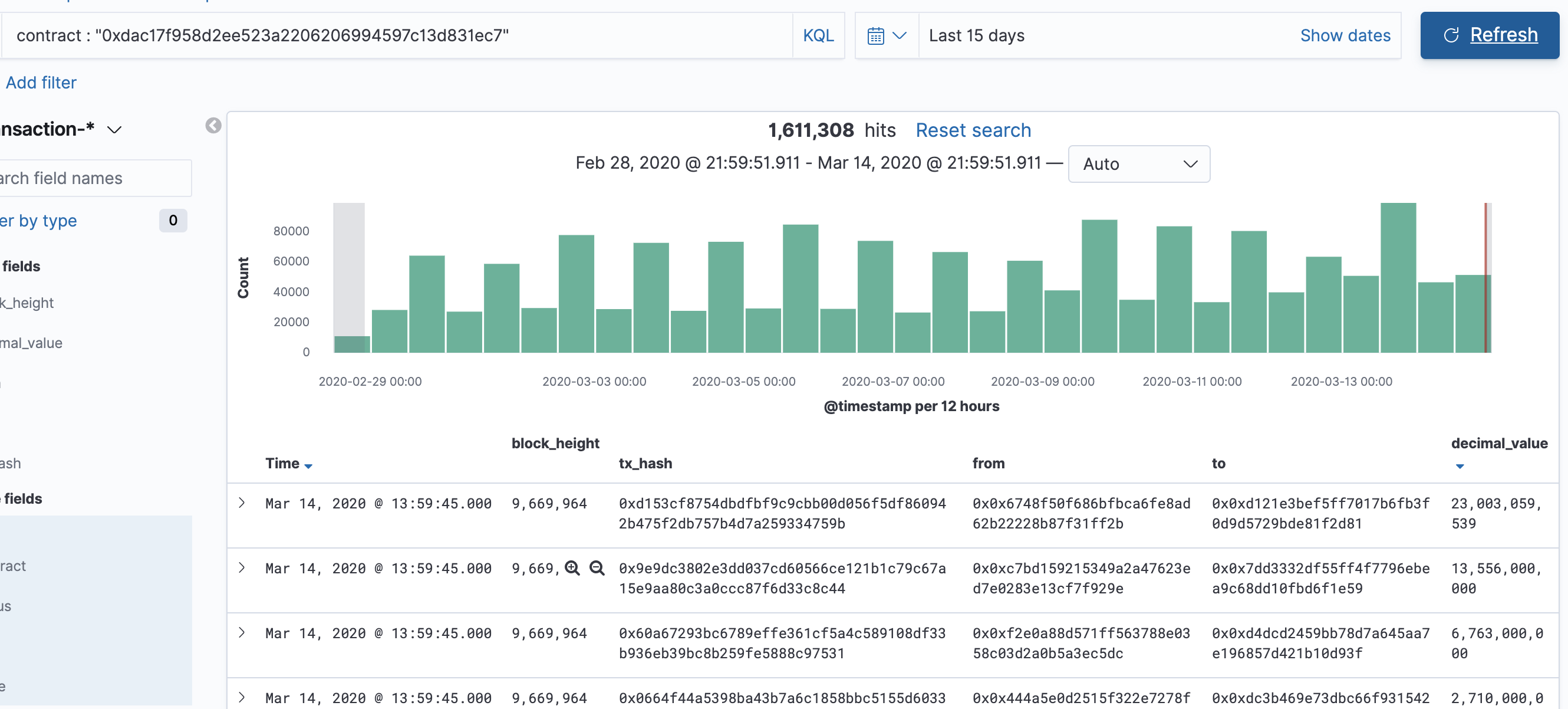 图 6 查询所有 USDT 交易 ### 交易分析 我们记录 type 1 为 ETH 交易,type 2 为 ERC20 转账,type 3 为合约创建。五年来 3 种交易类型整体趋势如下如。 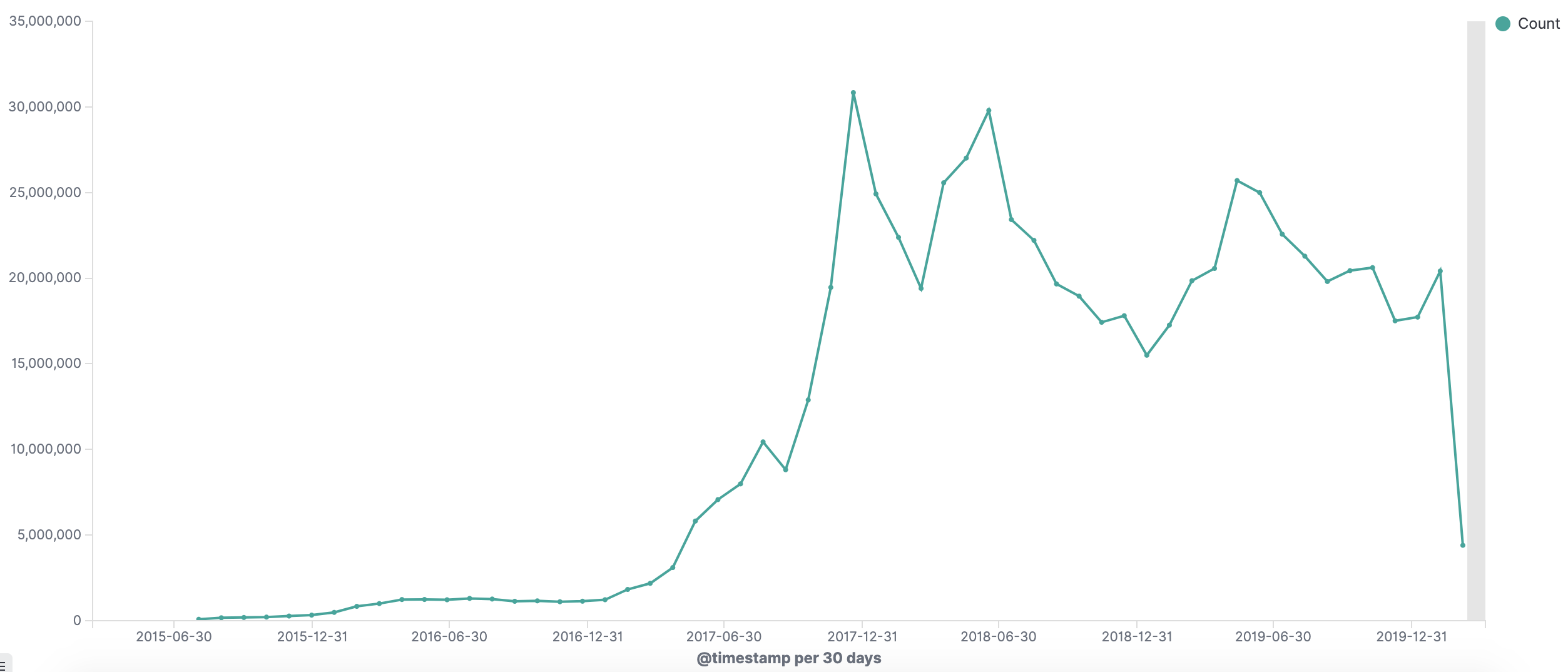 图 7 整体交易趋势 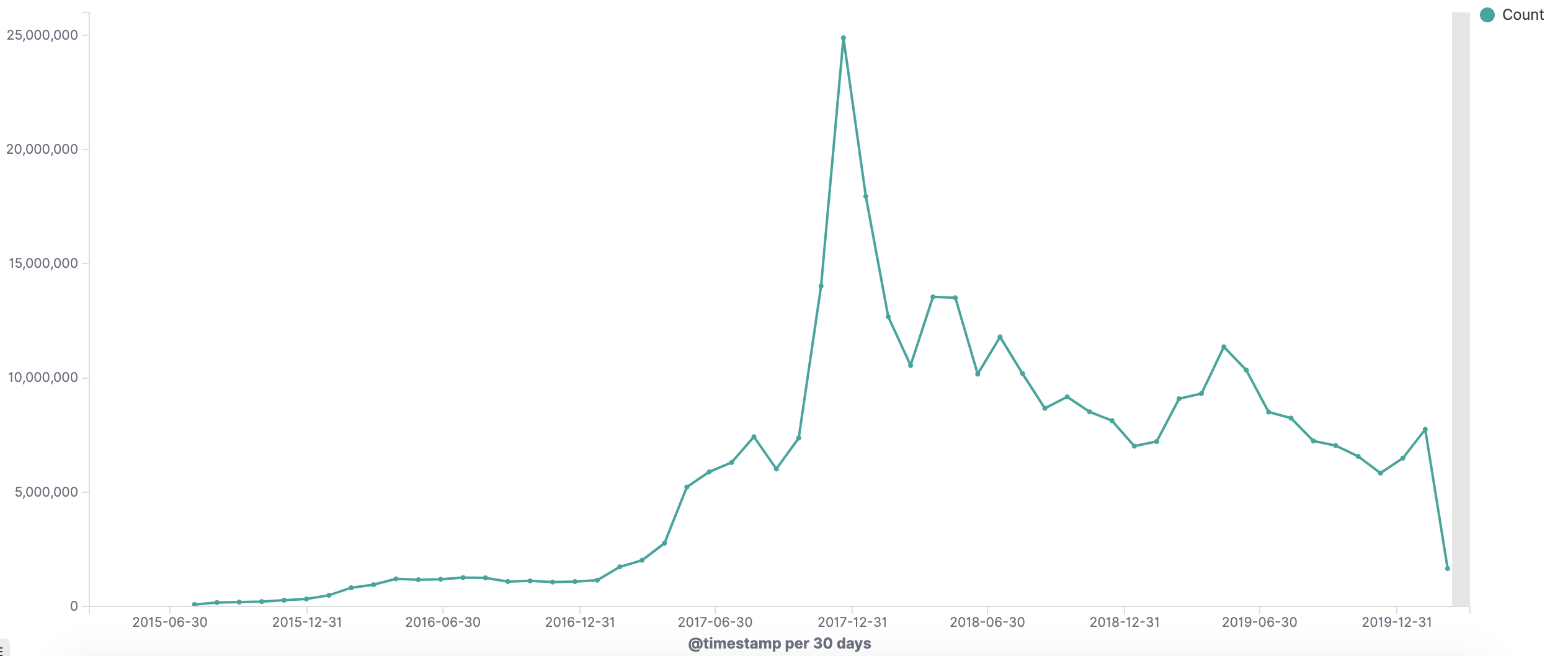 图 8 ETH 交易趋势 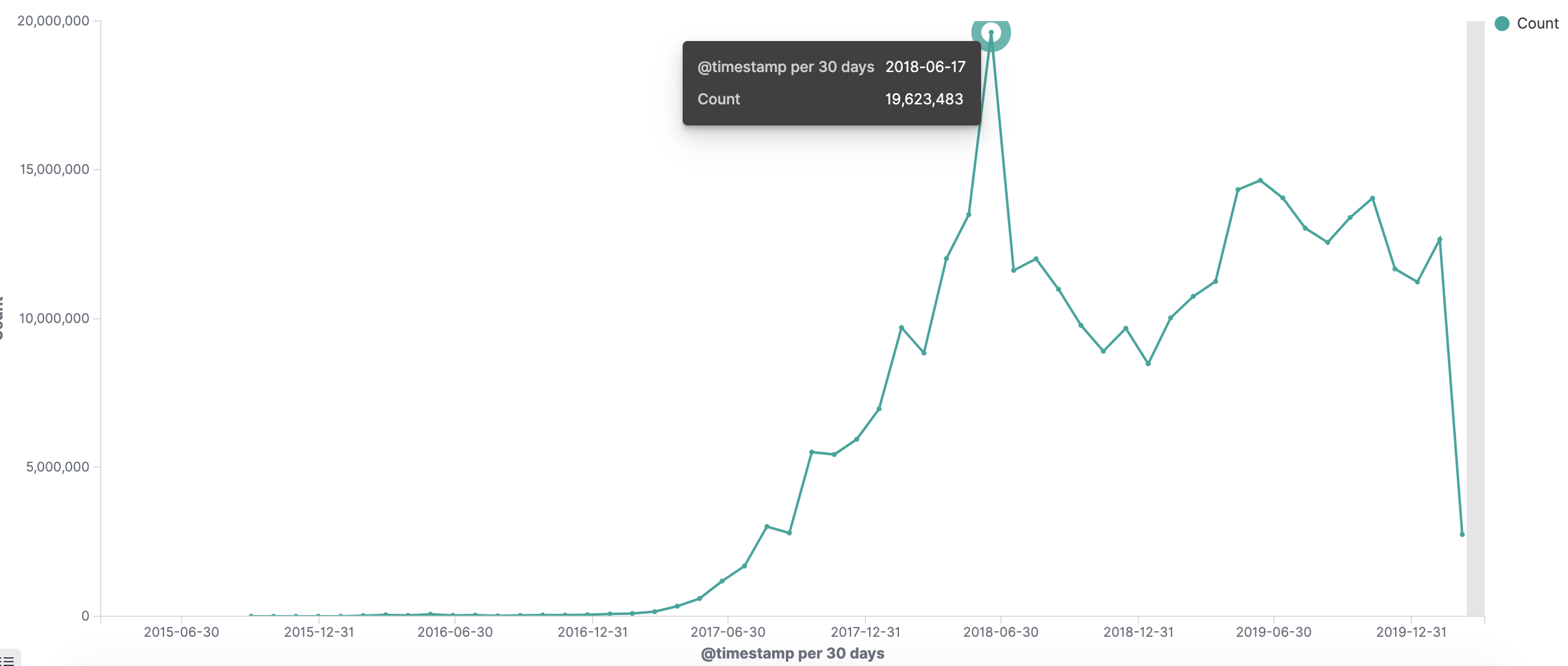 图 9 ERC20 交易趋势 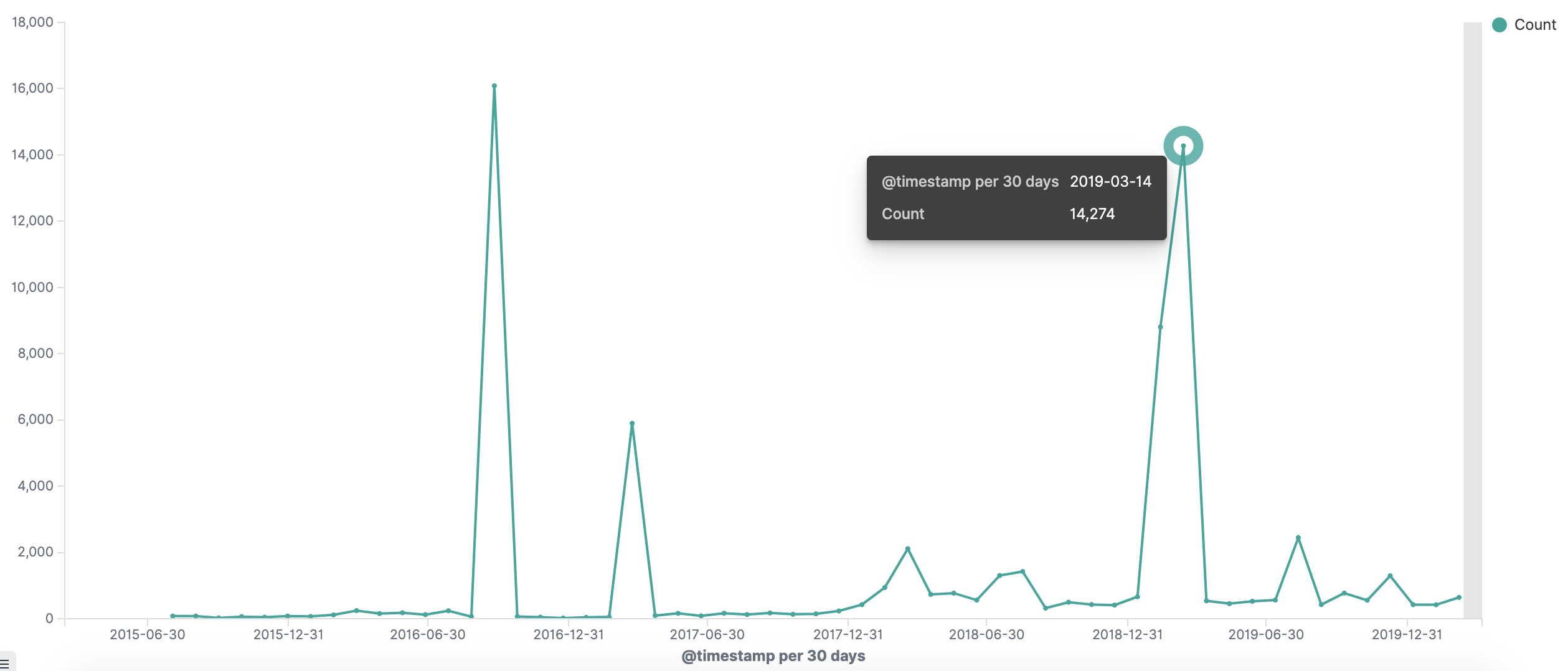 图 10 以太坊合约创建趋势 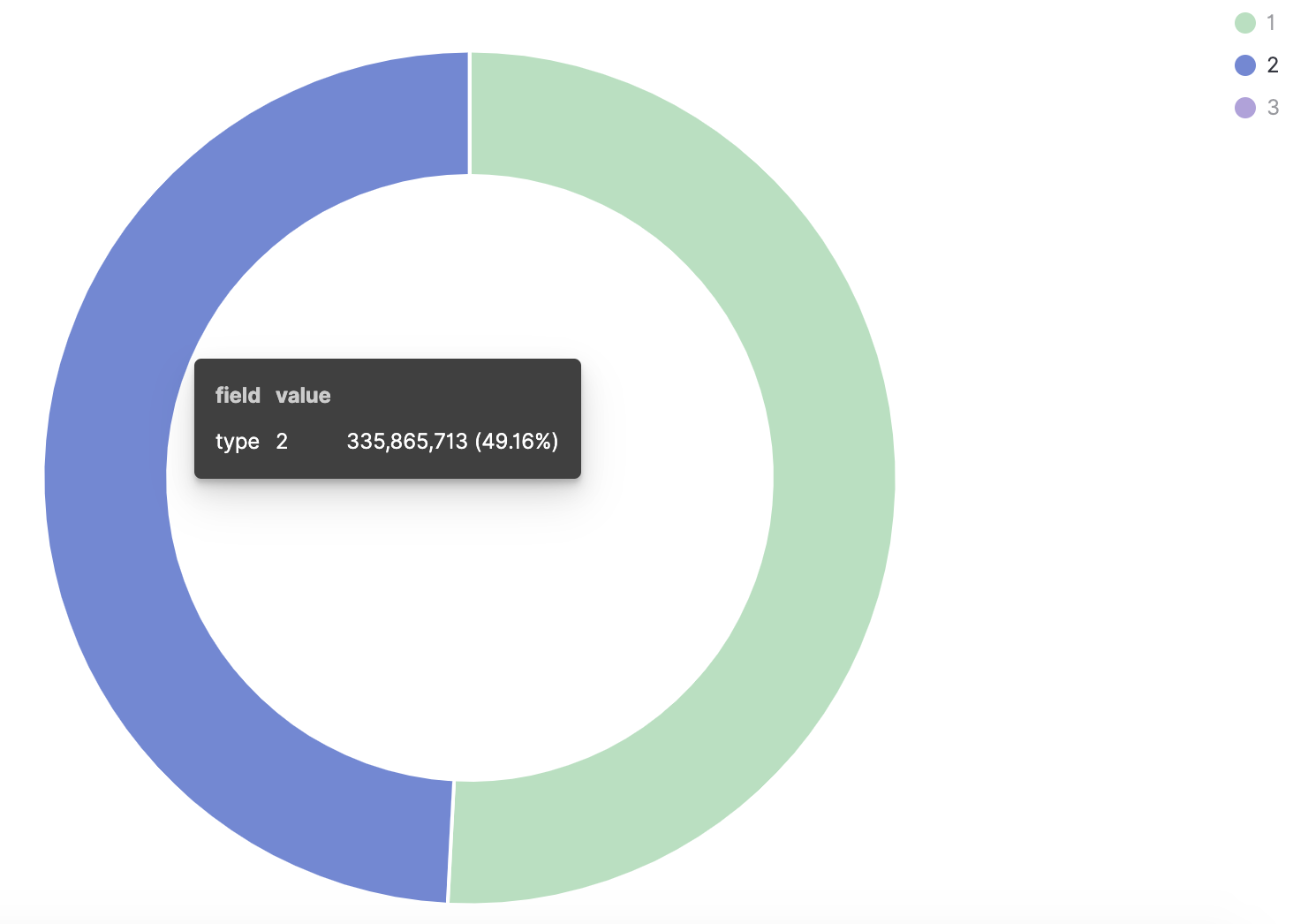 图 11 五年内三种交易类型占比 可见链上 ERC20 交易已经基本与 ETH 交易一样多,下面是两年内三种交易类型占比,ERC20 转账数量已经超过 ETH 转账数量。 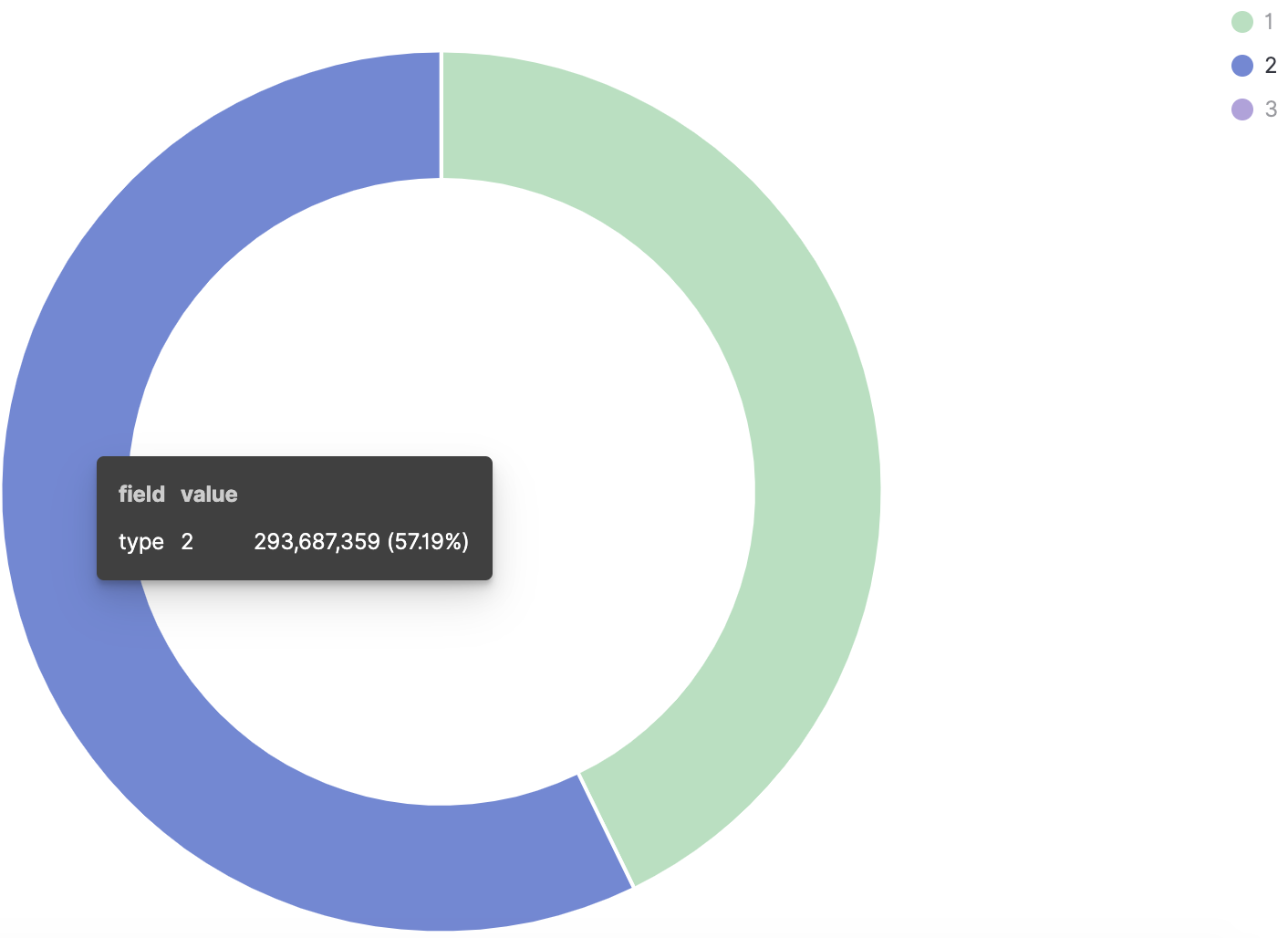 图 12 两年内三种交易类型占比 下图为两年内 ERC20 交易前十的 Token,USDT 稳坐第一。 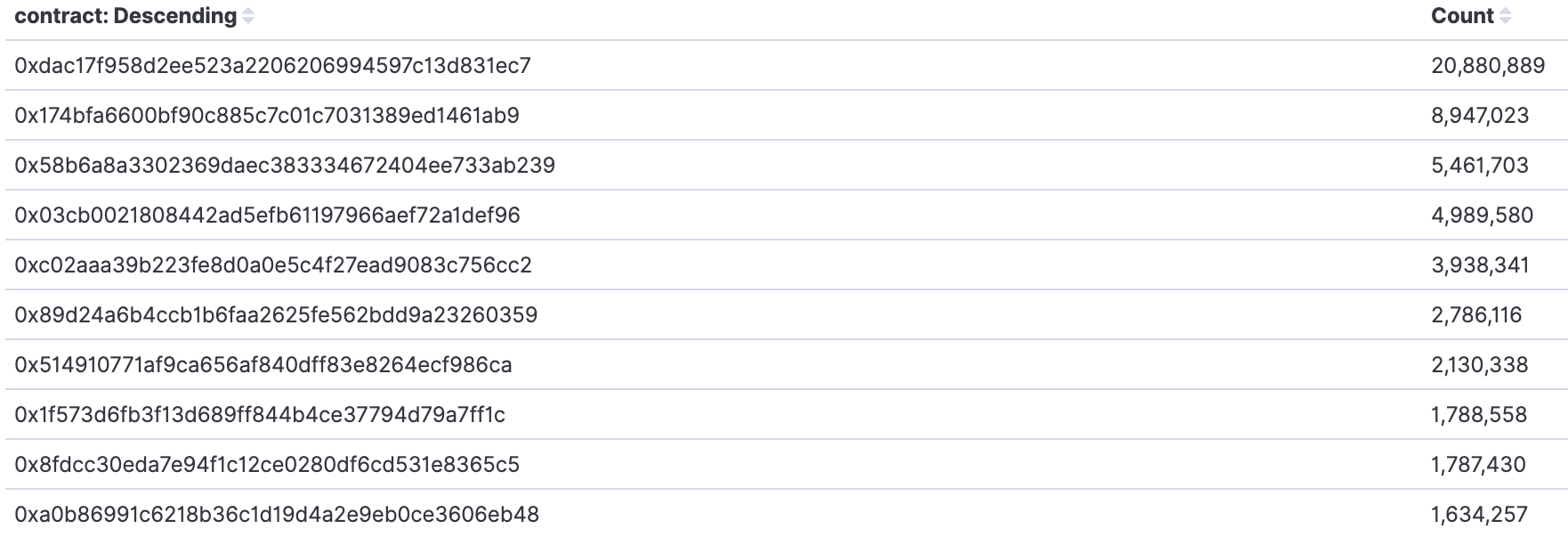 图 13 两年内前十交易量的 Token 我们也可以查询某个地址拥有的所有 ERC20 Token 类型及交易数量,比如 0x6465349f1a53ba0097d9aac3f6ef293bdd10cae1 共拥有 71 种 ERC20 Token,合约地址如下。 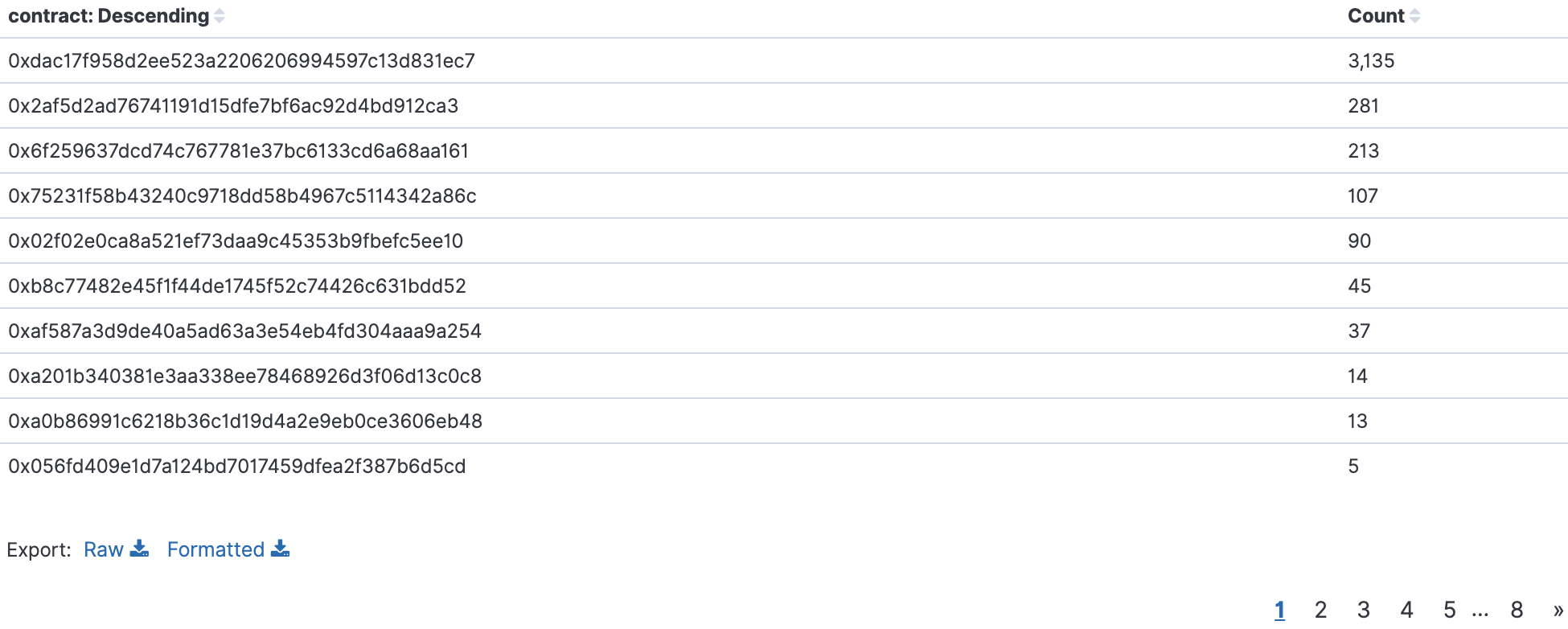 图 14 某地址拥有的所有 ERC20 种类 3.12 日晚上发生了暴跌,我们来看下一周内的 ETH 大额转账趋势,3.12 19:00 出现了一笔 14 万 7 千的 ETH转账。 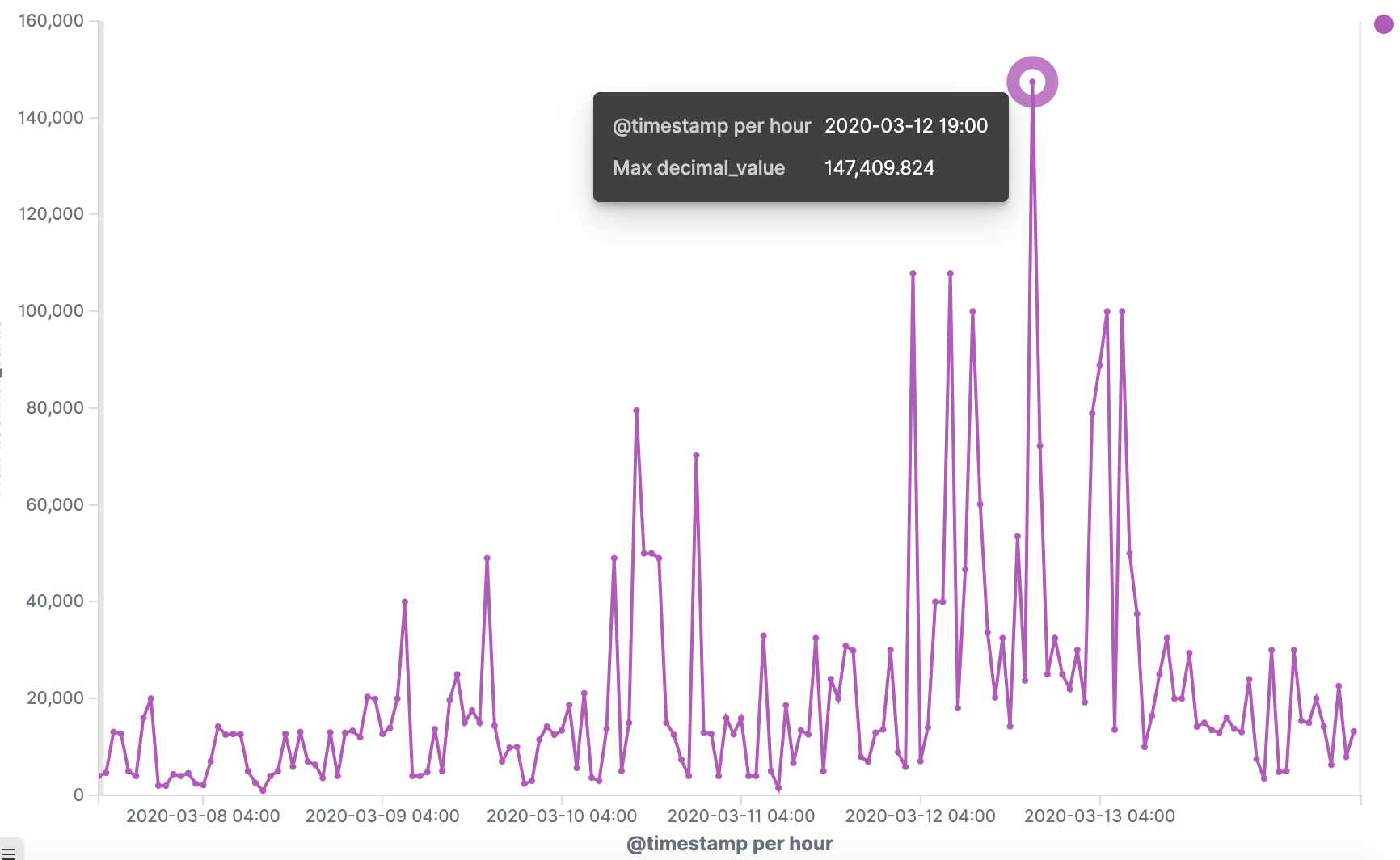 图 15 ETH 大额转账趋势 最近一周 USDT 大额额转账较多,其中 13 日交易 hash 为 0xd30eeca47682a2f35119c3a465e998b68cde1e94c317eee5851859cb6a6d1c44 进行了高达 7580 万的 USDT 转账。 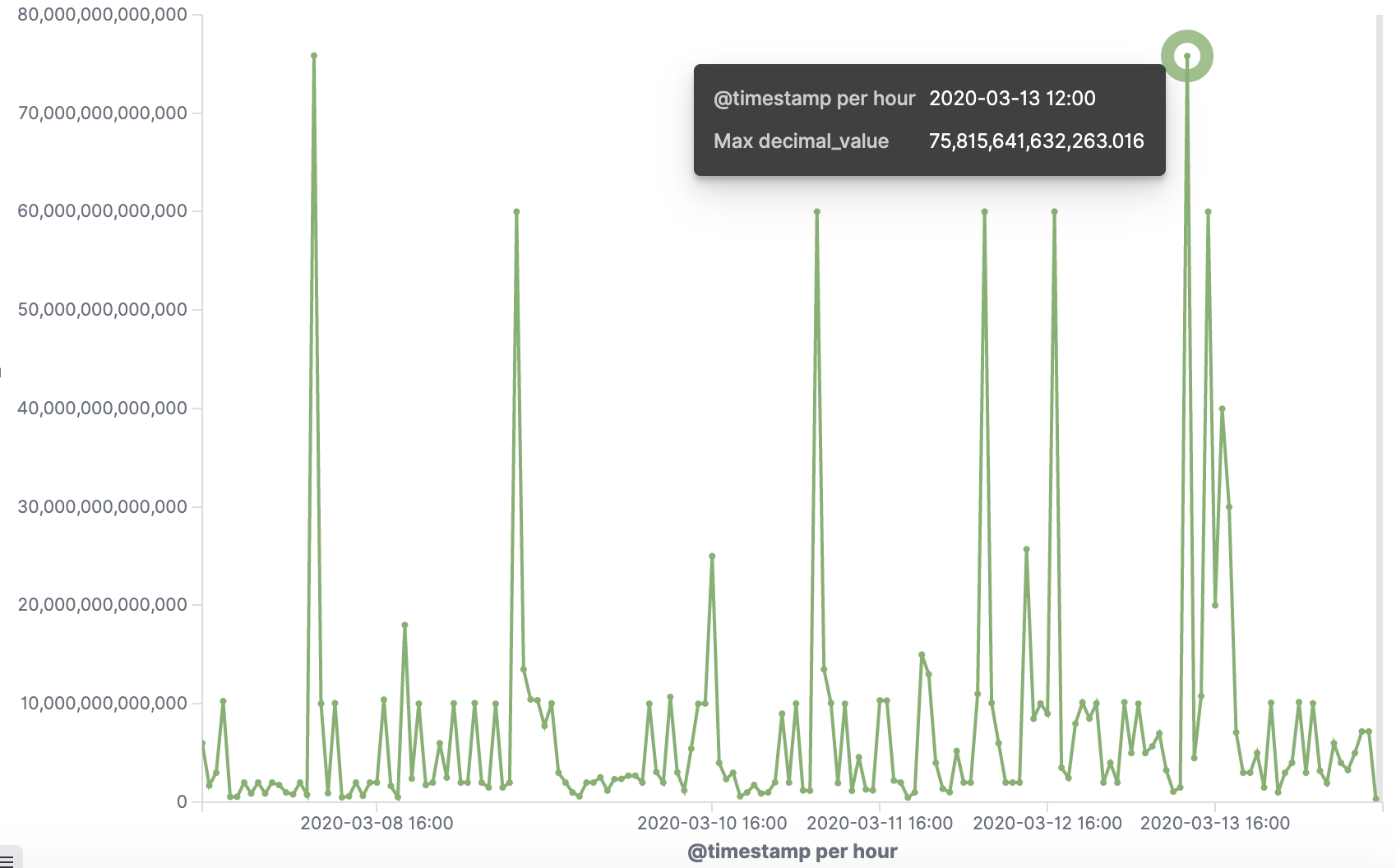 图 16 USDT 大额转账趋势 ## 总结 本文以以太坊区块链为例,对如何设计一款区块链浏览器从数据来源,完整性检查,数据持久化等方面进行了分析,最后通过解析全量数据对交易进行了统计分析。对于比特币为代表的 UTXO 类型区块链数据解析,方法一致,存储结构进行相应改变即可。